- Published on
Introducing VerifyML
- Authors
- Name
- Jason Ho
- @CylynxTweets


Introduction
Recently, we participated in the Global Veritas Challenge, a competition held by the Monetary Authority of Singapore (MAS) that
… seeks to accelerate the development of solutions which validate artificial intelligence and data analytics (AIDA) solutions against the fairness, ethics, accountability and transparency (FEAT) principles, to strengthen trust and promote greater adoption of AI solutions in the financial sector.
This post describes our solution to the Challenge: VerifyML.
Note 1: In this post, the term “bias” refers to the concept of injustice / unfairness, instead of bias in the statistical sense. Where it refers to the latter, it will be explicitly stated.
Note 2: Although FEAT refers to 4 different concepts, this Challenge’s main focus is on fairness.
Background
To understand the existing AI fairness landscape, we consulted research papers, interviewed experts, and surveyed existing tools in this space. Through this, we found that current solutions tended towards one of two approaches to tackle bias in machine learning (ML) models:
- Fairness through unawareness: Protected attributes (e.g. race, sex, age, etc.) in the dataset are excluded from model development — the idea being that if a model is not trained on those attributes, it is less likely to be biased towards/against any particular attribute subgroup. It is a clear, straightforward approach that is relatively easy to implement.
- Fairness through metric equality: Evaluate a model against a buffet of equality measures (e.g. disparities in predicted positive rates / false negative rates / false discovery rates across subgroups etc.) — a model is considered fair (or not unfair) if its performance falls within a user-specified metric equality threshold. Roughly speaking, this equates to adding more mathematical constraints for the model to optimise against.
Both approaches have their merits, but there are limitations to be considered as well:
- Fairness through unawareness does not prevent a model from approximating protected attributes via proxy variables (e.g. someone’s race could be inferred from their country of origin). The proxies could be removed as they are found, but it turns fairness efforts into a never-ending game of cat-and-mouse. Even with the best cats, subtler relationships between features might still go undetected! Furthermore, protected attributes are at times crucial to the broader business problem — for example, in the medical field, knowing someone’s age / sex can be essential information when prescribing suitable treatments and medication.
- Using only metric equality measures is insufficient, since it lacks human context. Fairness is, after all, an essentially contested concept — reducing it to mathematical formulas would not do justice to its inherent subjectivity. Instead of using them as a cure-all, the relevant measures and thresholds should be carefully selected only after a thorough discussion on an organisation’s own definitions of fairness.
Hence, we sought to create a framework that enables a holistic approach to building ML models — one that considers social/business contexts, operations, and model performance collectively. We felt that such a solution would combine the advantages described above, and align more closely with the spirit of MAS’ FEAT principles.
Solution
Thus was born VerifyML — an open-source governance framework to build reliable and fair ML models. It consists of three parts:

1. Survey Form
The first part is a web form to gather inputs and align stakeholders across product, data science, and compliance about model requirements. It enables comprehensive model assessments throughout the development process to keep everyone on the same page, and the answers can be continually refined to suit an organisation’s needs. Try it out with our demo web form and you can receive a copy of the responses in JSON format via email.
2. Model Card
Adapted from Google’s Model Card Toolkit, this is the source of truth for all information relating to a particular model. Using our Python library, a Model Card can be bootstrapped using the survey form response received via email, or created from scratch.
Rather than comparing across different metric measures aimlessly, we believe that fairness evaluation should be done with a more structured approach with guidance from an ethics committee. One approach which we find practical and effective is to identify groups at risk and ask whether any of the following definitions of fairness should be applied to them:
- Fairness as a minimum level of acceptable service — e.g. a minimum false positive rate threshold for all groups
- Fairness as equality — comparable levels of disparity between groups in particular outcomes of interest
- Fairness as equity — additional intervention justified on the basis of existing societal biases
Model tests can then be added to evaluate if a model meets various performance, explainability, and fairness criteria. Currently, VerifyML provides 5 types of tests:
- Subgroup Disparity Test: For a given metric, assert that the difference between the best and worst performing group is less than a specified threshold (i.e. metric equality / similarity, as previously discussed)
- Min/Max Metric Threshold Test: For a given metric, assert that all groups should be below / above a specified threshold
- Perturbation Test: Assert that a given metric does not change significantly after perturbing on a specified input variable
- Feature Importance Test: Assert that certain specified variables are not included as the top n most important features
- Data Shift Test: Assert that the distributions of specified attributes are similar across two given datasets of interest
These provide a way check for unintended biases or model drift over time. Given the variety, the choice of tests would differ from project to project, since it heavily depends on an organisation’s overall objectives (as previously defined in the survey form).
After a Model Card is created, the information is stored in a protobuf file, which can be exported into a HTML / Markdown file as a business report.
In addition, a model card can be compared against another side-by-side, enabling easy tradeoff comparison. For example, we might check how a model that uses protected attributes performs against an equivalent model that doesn’t (i.e. fairness through unawareness):
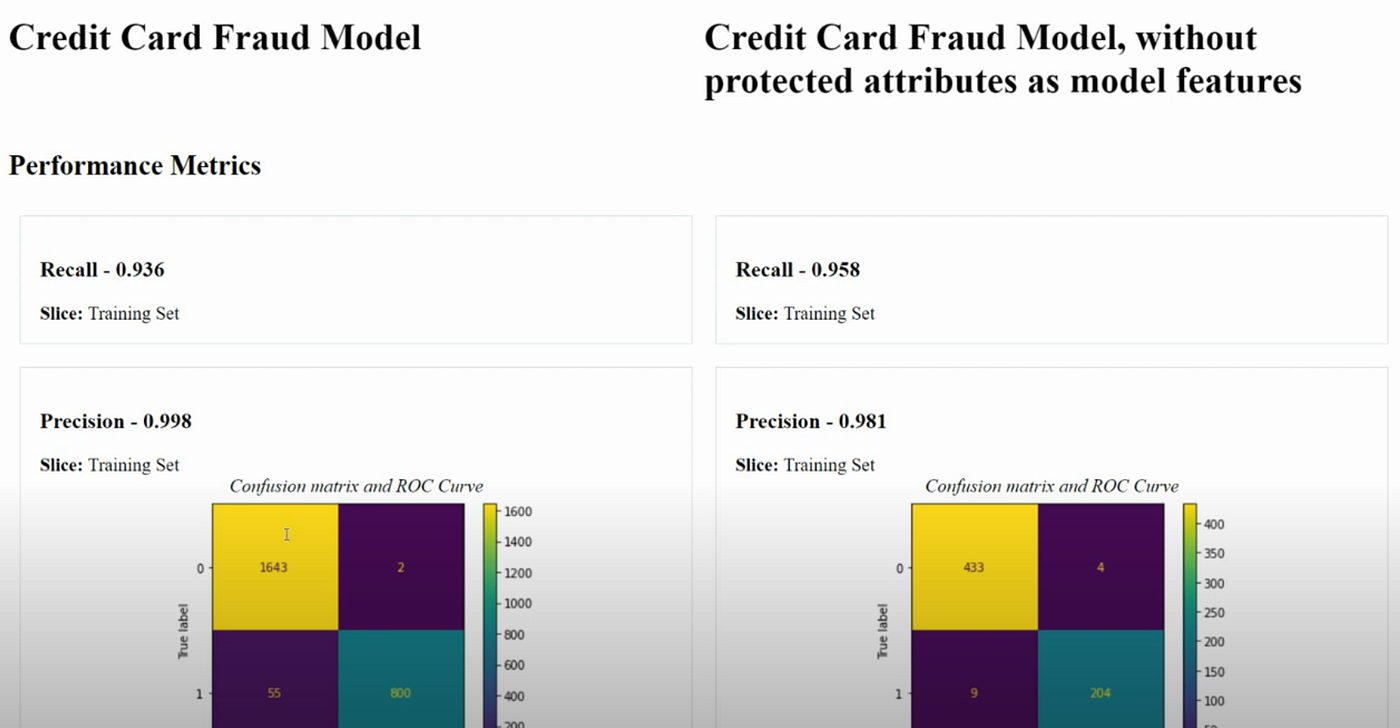
A tradeoff comparison between a model that uses protected attributes, against another that does not
With this information, we can make better decisions about which model to use — does the use case warrant higher recall? What are the business / human costs of using a model that has lower precision? Does it pass the fairness model tests? Thinking through and documenting answers to such questions helps an organisation reach informed and justifiable conclusions, regardless of whether protected attributes are used.
3. Model Report
A Model Report contains automated documentation and alerts from model test results generated via Github Actions. Like a typical unit testing CI/CD workflow, it can be set to validate a Model Card upon every Github commit, reporting a summary of the test results to all users in the repository. This provides foundation for a good development workflow, since everyone can easily identify when a model is production-ready, and when it isn’t.
Examples
To get an idea of how the workflow described above might look in practice, take a look at our example notebooks here.
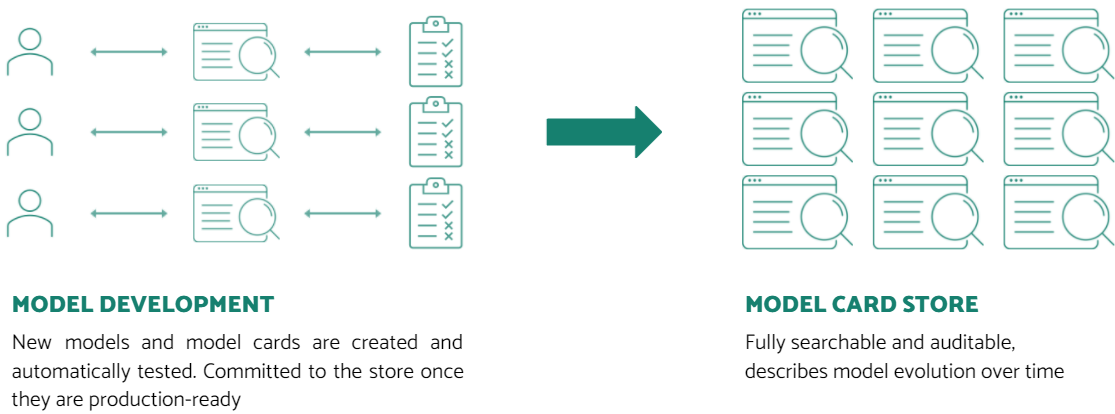
Vision
When implemented at scale, we imagine the core of VerifyML to be an easily searchable central Model Card store that contains full details of an organisation’s models (including third-party ones). Every time a new Model Card is developed, model tests are run automatically via separate workers, and all tests should pass before a card is committed to the store.
Conclusion
Current fairness solutions can be effective in the right context, but using them individually is insufficient for preventing bias in machine learning. VerifyML addresses this problem by merging them together and taking a more comprehensive approach to model development, allowing the strengths of each to overcome the limitations of another.
With its 3 components, VerifyML is a toolkit for teams to document findings and evolve along a model’s development lifecycle. It improves model reliability, reduces unintended biases, and provides safeguards in a model deployment process, helping its users work towards the goal of fairness through awareness.
Try it out by downloading the package, pip install verifyml and going through the examples in Github. Feel free to reach out through the Github repository for technical questions or through our contact-us page if you would like to collaborate with us on proof of concepts.
EDIT — If you’d like to get started with VerifyML, read our quickstart guides here: